The Transformer Model: How Artificial Intelligence Understands Language
When we talk about artificial intelligence, we often hear the term Transformer Model. We also learn that the emergence of the Transformer Model ushered in the current hot AI era. In this article, we’ll take a closer look at what the Transformer Model is and the role it has played in revolutionizing AI technology.
Introduction
Artificial intelligence is behind the smartphones, search engines, and many online services we use every day. The “transformer model” is one of the key technologies that has led to revolutionary advances in the field of natural language processing (NLP) in recent years. In this article, I’ll explain what the Transformer Model is and why it’s important to the field of NLP, while also providing insights into how it’s changing our digital experience.
The Transformer Model was first introduced by a team of researchers at Google in 2017. Compared to previous AI models, the Transformer Model represents a huge leap forward in the way textual data is processed. Whereas traditional models process text word-by-word, Transformer models can see the entire sentence at a glance and better understand the relationships between each word. Because of this ability, Transformer models have shown remarkable results in a variety of NLP tasks, including machine translation, summarization, sentiment analysis, and more.
This success of the Transformers model is not only advancing natural language processing technology, but it’s also having a positive impact on our everyday lives. For example, more accurate machine translation services are breaking down language barriers, making it easier for people around the world to communicate, and sentiment analysis techniques are helping to improve the quality of customer service.
In this article, you will gain a basic understanding of how the Transformer Model is revolutionizing the field of NLP. Furthermore, you will learn how this technology is making a positive difference in our lives and society. We have tried to break down the complex and technical content into as simple and understandable language as possible, so that even those who do not have a deep knowledge of artificial intelligence technology can easily enter the magical world of the Transformer Model.
By understanding the potential of this technology, we can expand our imagination of what positive opportunities future AI technologies can provide for humanity. Therefore, the value you get from reading this article is not just technical knowledge, but envisioning what a future society could look like. Now, let’s dive into the fascinating technology of the Transformers model together.
Foundations of AI and Natural Language Processing: A Deeper Dive into RNNs and LSTMs
As artificial intelligence (AI) permeates every aspect of our lives, natural language processing (NLP) is becoming increasingly important. By equipping computers with the ability to understand and produce human language, NLP is driving innovation in areas as diverse as search engine question and answer, speech recognition technology, and automatic translation. Underpinning these advances are important models such as Recurrent Neural Networks (RNNs) and Long Short-Term Memory (LSTM) networks.
RNNs: Understanding Recurrent Neural Networks
An RNN is a neural network structure specifically designed to process sequential data. They are effective when dealing with information where order is important, such as text or speech data. The key idea behind RNNs is “memory”: they remember information they’ve processed before, and use that information to make current decisions. This allows them to take into account the order and context of words within a sentence.
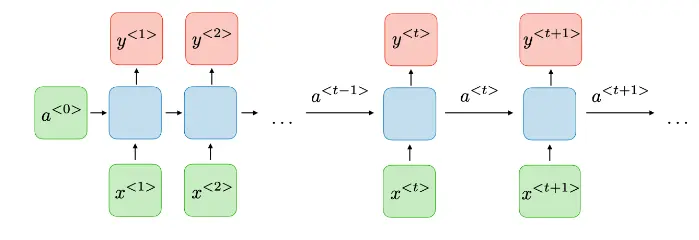
- Simple recurrent: RNNs have a very simple structure, taking an input x and a previous hidden state a at each time step and producing the current hidden state a and output y.
- Short-term memory: RNNs have a limited ability to remember previous information over time, so their performance tends to decrease as the sequence gets longer.
- Continuity: The output of the previous time step is used directly as input for the next time step, and so on for every time step.
However, RNNs face two major problems. First, the “vanishing gradient” problem makes it difficult for the model to learn when dealing with long sequences. This makes it difficult for RNNs to remember information earlier in the sequence for long periods of time. Second, the sequential way of processing data makes parallel processing difficult. This is one of the main reasons why the learning process takes so long.
LSTM: Innovations in long-term short-term memory networks
LSTMs are models designed to overcome these limitations of RNNs. At the core of LSTMs is the concept of ‘cell states’. Cell states provide a mechanism for passing information through the network over long periods of time. This allows LSTMs to effectively address the problem of long-term dependency.
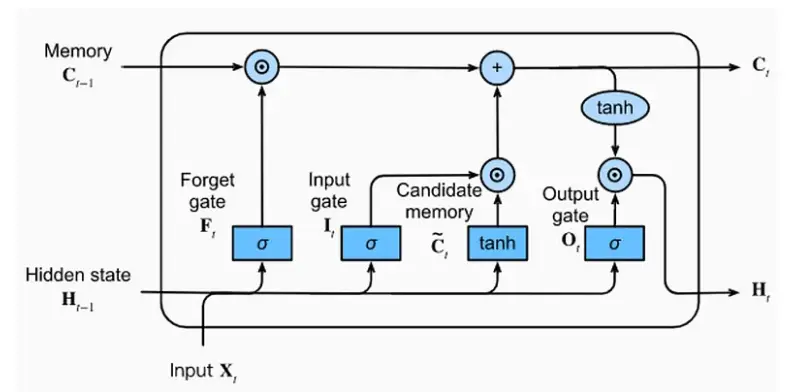
- Gate mechanism: LSTMs introduce special structures called “gates” to provide finer control over data flow. This allows for long-term memory of information and the ability to remove information that is not needed.
- Memory cells: Ct is the heart of the LSTM, the memory cell responsible for long-term memory. It stores the flow of information over time, and is updated through gates.
- Complex state management: LSTMs use input gates, delete gates, and output gates to retain or delete information and add new information to memory in a complex process.
- LSTMs also introduce structures called “gates” to finely control the flow of information. These gates determine what information is added to or removed from the cell state. This structure allows LSTMs to retain the information they need for longer periods of time while removing unnecessary information, allowing them to more accurately learn complex patterns in textual data.
Limitations of RNNs and LSTMs and the transition to transformers
The differences between RNNs and LSTMs are as follows
- Information management capabilities: LSTMs have more advanced information management capabilities compared to RNNs, which helps solve the problem of long-term memory.
- Structural complexity: Compared to RNNs, LSTMs are more structurally complex, but this allows them to perform more challenging sequence processing tasks.
- Performance: LSTMs overcome the performance limitations of RNNs and perform particularly well on long sequence data.
Although LSTMs have solved many of the problems of RNNs, they still suffer from difficulty in parallel processing and high computational cost. These issues are especially pronounced when dealing with large datasets. To overcome these limitations, transformer models have emerged. Transformers enable parallel processing by processing the entire sequence at once through a self-attention mechanism, effectively solving the long-term dependence problem and gradient vanishing problem encountered by RNNs and LSTMs.
In conclusion, while RNNs and LSTMs have made great contributions to the advancement of NLP, the emergence of transformer models has enabled higher levels of language understanding and processing. We are now ready to take a closer look at how transformer models are driving new innovations in natural language processing.
The rise of the transformer model
In the evolution of artificial intelligence and natural language processing, the advent of the Transformer model was a true game changer. Introduced in 2017, it fundamentally changed the way language is understood and created, bringing a new wave of innovation to the field of NLP.
Introducing the Transformer Model
The core of the Transformer model lies in its ‘Attention Mechanism’. This mechanism allows the model to identify which other words in the input sequence are most relevant to each word in the sentence, and to determine the meaning of the sentence based on these relationships. The transformer as a whole consists of two main components: an ‘Encoder’ and a ‘Decoder’, which are responsible for processing the input text and generating new text based on what they understand.
Structure and limitations of RNNs and LSTMs:
RNNs receive input at each time step, compute a new state based on the previous state, and generate output. This structure is sequential, which makes it difficult to parallelize, and it suffers from the “long-dependency problem,” which is the difficulty of retaining important information when processing long sequences.
LSTMs are designed to overcome the limitations of RNNs by introducing a mechanism called a “gate” to retain important information for longer periods of time and forget unnecessary information. This makes them more resistant to the long-term dependence problem than RNNs, but still limits their parallelism.
Innovations in the Transformer Model:
To overcome this limitation, Transformer uses an “attentional mechanism” that allows it to process each element in a sequence independently. It has the following key features
- Self-attention: This mechanism allows the model to see the relationship between each word by looking at the entire sentence at once. It evaluates the importance of each word and summarizes the information according to its weight.
- Parallel processing: Since the transformer can process each element of a sequence simultaneously, it allows for parallel processing, which greatly speeds up learning.
- Encoder and decoder: Transformer models process input data with an encoder and generate an output sequence based on that information with a decoder. Each encoder and decoder consists of multiple layers, each containing a self-attention and feedforward neural network.
Improved results:
These differences have led to the following improvements in transformer models
- Improved learning efficiency: It can learn large datasets faster due to its parallel processing power.
- Better learning of long-term dependencies: Thanks to its self-attention mechanism, it is better at learning relationships between words that are far apart in a sentence.
- Improved performance on a variety of NLP tasks: Delivers better results than traditional RNNs or LSTMs in machine translation, text summarization, question answering systems, and more.
Applications of Transformer Models: Focusing on GPTs and BERTs
The innovative structure of transformer models has opened up a wide range of applications in natural language processing (NLP). In particular, two models based on this technology, Generative Pre-trained Transformers (GPTs) and Bidirectional Encoder Representations from Transformers (BERTs), are playing an important role in solving many challenges in NLP.
Introduction to GPTs and BERTs
GPTs are models focused on text generation that can be pre-trained on large datasets and then fine-tuned for specific tasks. The model is able to understand the context of a given piece of text and generate a natural continuation of the text accordingly. This ability can be utilized in a variety of fields, such as chatbots, creative writing, and even code generation.
BERT is a model that focuses on understanding the bi-directional context of text. BERT is particularly effective at tasks that involve determining the meaning of text, such as text categorization, entity name recognition, and question answering systems. BERT’s ability to learn in both directions allows the model to better understand the context of a sentence as a whole, which leads to more accurate predictions and analysis.
Applications in different NLP tasks
Transformer models, especially GPT and BERT, are showing innovative results in a variety of NLP tasks.
- Machine translation: Transformer models are able to understand the full meaning and context of a sentence, which has greatly improved the accuracy and naturalness of machine translation.
- Text summarization: These models can be used to identify and summarize important information, and are useful for succinctly presenting the key points of news articles or long documents.
- Question answering systems: Models like BERT excel at understanding a user’s question and finding the correct answer in relevant databases or documents.
- Sentiment analysis: Accurately determining sentiment or opinion from text is an important application in customer feedback analysis, market research, and many other fields. Transformer models are also very useful for such sentiment analysis tasks.
As you can see, the transformer model has a wide range of applications, and GPT and BERT are some of the most successful examples based on this model. These techniques are driving the field of NLP forward and are expected to bring more innovations in various fields in the future. Advances in these models are fundamentally changing the way AI understands and uses human language, which is having a positive impact on the way we live and work every day.
The future and challenges of transformer models
The transformer model has led to revolutionary advances in artificial intelligence and natural language processing (NLP). However, the evolutionary path of this technology and the challenges it faces remain a major concern. Understanding and addressing these challenges will play a crucial role in the future development of the transformer model.
Technological advances
The future of transformer models is likely to be even brighter with constant innovation and improvement. The size and power of models will continue to increase, which will make them more sophisticated and applicable to a wider range of tasks. Research will also be focused on making transformer models more efficient and accessible, which will allow them to achieve high-quality results with fewer data and computational resources.
We’ll also see an expansion of applications in a variety of fields. Already used in machine translation, text generation, sentiment analysis, and more, we expect to see an increase in the use of transformer models in other specialized fields such as healthcare, law, and education. In addition, research will continue to improve human-machine interaction, which will give rise to new forms of user interfaces and applications based on transformational models.
Challenges
Despite the advances and proliferation of transformer models, there are still significant challenges to overcome. First, training large-scale transformer models requires enormous amounts of data and computational resources. This raises cost and environmental concerns, and can limit the accessibility of the model.
Second, transformer models can sometimes produce unpredictable outputs, which can be a big problem, especially in sensitive applications. Therefore, research is needed on how to better understand and control the model’s predictions.
Third, data bias and fairness issues affect all AI systems, including Transformer models. If a model learns from biased data, its results can be biased as well, so it’s important to keep working to address this issue.
The bottom line
Transformer models have truly revolutionized the field of artificial intelligence and natural language processing (NLP). Their emergence has opened up new ways to understand text more deeply and efficiently, moving beyond traditional sequential and limited models. Transformer-based models such as GPT and BERT have already demonstrated the practical value of this technology, performing well on a variety of NLP tasks, including machine translation, text summarization, and question answering systems.
The future of transformer models is only going to get brighter as technology advances and challenges are overcome. Research to increase the size and efficiency of models, expanding their application to different domains, and finding solutions to bias and fairness issues are key challenges facing transformer models. These efforts are essential for transformer models to understand and produce human language more accurately, which will further advance the future of artificial intelligence.
In this article, we hope you’ve gained an understanding of the basic structure of the transformer model, its key applications, and the challenges facing this technology. We also hope you’ve gained insight into how it can bring positive change to our society and our daily lives. More than just a technological innovation, the Transformers model is fundamentally changing the way we understand the world and interact with each other. This transformation will continue for years to come, bringing new opportunities and challenges for us all.
References
- “Attention Is All You Need” – This paper by Vaswani et al. introduces the transformer model, marking a shift from previous sequence transformation models that relied on recurrent neural networks (RNNs) or convolutional neural networks (CNNs). By using self-attention mechanisms to process data in parallel, transformer models improved efficiency and performance in a variety of NLP tasks. This work paved the way for later models such as GPT and BERT, and revolutionized the way language is understood and created.
- “Transformer models: an introduction and catalog” – While not the original paper introducing transformer models, this article provides a comprehensive overview and catalog of transformer models’ architecture, variants, and applications. It’s an excellent resource for demonstrating the impact of transformer-based models in a variety of AI and NLP tasks. The paper broadens the applicability of the transformer architecture, and goes beyond NLP to highlight its use in fields such as computer vision and audio processing.





